O dado pseudonimizado é um dado protegido pela Lei Geral de Proteção de Dados?
sexta-feira, 21 de agosto de 2020
Atualizado às 09:02
Texto escrito por Isadora Maria Roseiro Ruiz
Como toda novidade normativa, a Lei Geral de Proteção de Dados (lei 13.709/2018) também passará por várias análises, interpretações, críticas e estudos. Não por um capricho, mas, por trazer novos conceitos, normas e aplicações e, às vezes, até mesmo vocabulário.
Como forma de contribuir na evolução e construção do debate envolvendo a LGPD, o terceiro texto da Coluna Migalha de Proteção de Dados irá abordar duas palavras, e suas consequências, trazidas por esse novo sistema legal. São elas: anonimização e, em especial, pseudonimização.
Os termos, até então, não faziam parte do extenso e primoroso vernáculo jurídico e, como em outros aspectos da LGPD, exigem dos profissionais uma expansão em seus conhecimentos, demandando estudos interdisciplinares, e alargamento de informações. É o direito enfrentando a era tecnológica.
Dessa forma, fez-se necessário conceituar determinados termos, criando, assim, uma base de conhecimento comum a todos para a aplicação da lei. O art. 5 foi incumbido desta missão e, dentre outros, traz o conceito de dado pessoal, dado pessoal sensível, dado anonimizado e anonimização; todos importantes para a continuidade desse texto.
I - dado pessoal: informação relacionada a pessoa natural identificada ou identificável;
II - dado pessoal sensível: dado pessoal sobre origem racial ou étnica, convicção religiosa, opinião política, filiação a sindicato ou a organização de caráter religioso, filosófico ou político, dado referente à saúde ou à vida sexual, dado genético ou biométrico, quando vinculado a uma pessoa natural;
III - dado anonimizado: dado relativo a titular que não possa ser identificado, considerando a utilização de meios técnicos razoáveis e disponíveis na ocasião de seu tratamento;
XI - anonimização: utilização de meios técnicos razoáveis e disponíveis no momento do tratamento, por meio dos quais um dado perde a possibilidade de associação, direta ou indireta, a um indivíduo;
Temos a anonimização como uma solução para a remoção de informações de um documento1, agindo de tal forma que os dados capazes de identificar e individualizar uma pessoa, tais como nome, endereço e telefone, passam por processos que o tornam dados anonimizados.
Os processos pelos quais os dados pessoais podem passar para tonarem-se anonimizados são vários e não há, até então, diretrizes nacionais para uma definição sobre quais os parâmetros ou medidas mínimas que garantam a segurança dessa anonimização, ou seja, a segurança de que esses dados pessoais não permitam a associação, direta ou indireta, a um indivíduo.
A importância da anonimização é que, uma vez anonimizados, esses dados, em tese, não teriam a capacidade de identificar uma pessoa natural, por isso, não são tidos como dados pessoais2 e, consequentemente, não são mais protegidos pela lei. Para compreender que o estado de anonimato pode não ser permanente é de extrema valia. A própria lei, em seu art.12, considera o processo de reversão da anonimização o que ocorre quando são aplicados procedimentos capazes de reverter o anonimato do dado, de tal forma que estes tornam-se dados pessoais novamente e, portanto, sujeitos às proteções da LGPD.
O estudo interdisciplinar nesse assunto fornece uma singela amostra da necessidade de conhecimentos mais técnicos na área, como o fato de que não é possível a anonimização em absoluto de determinado dado e este continuar a ser útil para análises, informações e conhecimento3. Assim, a cautela e a prudência devem ser lembradas pois, em tese, todo dado anonimizado está sujeito a ser revertido e passível de identificação de seu titular.
É possível observar que a anonimização é devidamente tratada na LGPD, que traz conceitos, aplicação e escopo de proteção. Diferentemente do que ocorre com a pseudonimização. Esta, por sua vez, é mencionada expressamente apenas duas vezes no texto da lei, no artigo 13 e, em seção destinada aos dados pessoais sensíveis; em contraste com o capítulo de disposições preliminares, local onde se encontra a anonimização.
A pseudonimização é uma técnica que substitui informações contidas num conjunto de dados que identifica um indivíduo4 por um identificador artificial, um pseudônimo. Consideremos um conjunto de dados formados por dois tipos de dados, os dados pessoais, tais como nome e endereço, e demais dados que não singularizam a pessoa5. Na pseudonimização, os dados pessoais são substituídos por um identificador artificial e mantidos num banco de dados separado que liga dados pessoais e pseudônimo. Enquanto isso, os demais dados relativos à pessoa são referenciados por este pseudônimo e mantidos numa segunda base de dados. Desta maneira o processo de reidentificação só ocorre com a junção das duas bases de dados, ou seja, da base com os pseudônimos que os associa aos dados pessoais e os demais registros.
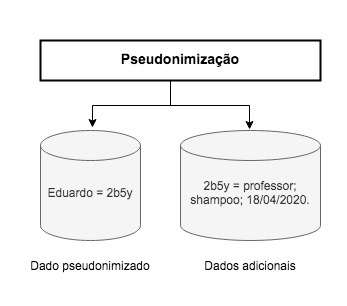
Utilizemos de um exemplo6 para uma compreensão mais facilitada e para notar o quão inserida na atualidade essa discussão está.
Peguemos um tipo de empresa que está em alta em época de pandemia: uma empresa que faz entrega de produtos. Essa empresa processa dados, tais como: a distância percorrida pelos motoristas, a frequência e os tipos de viagens realizadas. Esses dados são considerados como pessoais, pois são dados relacionados aos motoristas. A empresa utiliza esses dados por dois motivos: (1) para calcular as despesas com as viagens; e (2) para cobrar os clientes pelo serviço. A identificação do motorista é essencial para realizar esses estudos.
Porém, um departamento dessa empresa também utiliza esses dados para otimizar a eficiência das frotas e, para esse propósito, não é necessário a identificação do motorista.
Portanto, a empresa se assegura de que esse departamento apenas tenha acesso aos dados em um formato em que não seja possível individualizar e identificar os motoristas. Ela utiliza uma técnica de pseudonimização para substituir identificadores tais como nome, cargo e histórico de navegação por um identificador artificial (um pseudônimo) como, por exemplo, uma sequência de números que, por si só, não possui significado algum.
Os membros desse departamento só terão acesso aos dados pseudonimizados. No entanto, a empresa, como controladora, tem a capacidade de unir os dados originais aos dados pseudonimizados, tornando possível a (re)identificação dos motoristas.
Em termos legais, a pseundonimização teve seu conceito tratado primeiramente no General Data Protection Regulation (GDPR), o regulamento europeu de proteção de dados. Aqui no Brasil, a LGPD trouxe sua definição no parágrafo 4º do art.13:
§ 4º Para os efeitos deste artigo, a pseudonimização é o tratamento por meio do qual um dado perde a possibilidade de associação, direta ou indireta, a um indivíduo, senão pelo uso de informação adicional mantida separadamente pelo controlador em ambiente controlado e seguro.
Notemos que há uma sintonia entre o GDPR e a LGPD quanto à pseudonimização. Em ambas normativas o texto legal é similar e não dispõe expressamente quanto ao dado pseudonimizado ser ou não um dado pessoal e, portanto, sujeito à proteção da lei.
Porém, o GDPR resolve esse problema com os chamados recitais que funcionam como uma espécie de conjunto de prerrogativas e instruções que devem ser obedecidas quando da aplicação da lei.
Os recitais7 26 e 28 determinam que dados pseudonimizados permaneçam sob a proteção dos dados pessoais. Isso pois a utilização de técnicas de pseudonimização, apesar de possuírem o potencial de reduzirem o risco da exposição dessas informações pessoais e servirem como mecanismos de auxílio para os controladores e processadores cumprirem com sua obrigação de protegerem esses dados, continuam com o potencial de serem atribuídos aos seus titulares.
O recital 26 também diz que os princípios da proteção de dados devem ser aplicados para qualquer informação relacionada a um indivíduo identificado ou identificável. Diz, ainda, que dados pessoais que foram pseudonimizados e que podem ser atribuídos a uma pessoa natural com o uso de informação adicional, devem ser considerados informações de indivíduos identificáveis.
O que se entende desses dois recitais acima mencionados é de extrema importância pois uma vez que se determina que dados capazes de tornar um indivíduo identificável devem ser considerados dados pessoais, entende-se que dados pseudonimizados são dados pessoais, pois eles possuem o poder de (re)identificar determinado indivíduo.
Como dito anteriormente, a LGPD no Brasil foi espelhada no GDPR e esse espelhamento deve ser estendido com a adoção do entendimento de que dados pseudonimizados devem ser equiparados aos dados pessoais e, portanto, protegidos pela LGPD.
Tal entendimento vai ao encontro com o objetivo da lei que, em seu artigo 1º, diz que a lei tem por objetivo a proteção de direitos fundamentais de liberdade e de privacidade e o livre desenvolvimento da personalidade da pessoa natural. Também encontra respaldo nos princípios norteadores da lei que, elenca em seu artigo 2º, dentre outros princípios, o de respeito à privacidade (inciso I), a inviolabilidade da intimidade e da honra (inciso IV).
Há, também, uma razão técnica que justifica o dado pseudonimizado ser um dado protegido pela LGPD, é que, atualmente, os dados relativos à pessoa natural podem possuir uma alta dimensionalidade.
Isso significa que um indivíduo pode ser identificado por meio de mais de um tipo de conjunto de dados. Uma pessoa é normalmente identificada por seu nome, telefone, endereço e CPF, por exemplo. Esse tipo de dado é chamado de identificador direto8, ou seja, são atributos, características, que identificam explicitamente um indivíduo. Mas há, também, os chamados identificadores indiretos que, em conjunto, são capazes de identificar um indivíduo. Como exemplo, podemos citar os dados que um supermercado ou farmácia armazena das compras feitas por seus clientes, ou seja, aquele conjunto de dados do perfil de compra determina, singulariza uma pessoa.
Temos, dessa forma, que a pseudonimização, para ocorrer, substitui os dados diretos por uma identificação artificial (ver Figura 1) e armazena essa associação em um banco de dados separado. Porém, ainda persistem os demais dados, que são os identificadores indiretos. E esses identificadores indiretos, ao serem analisados conjuntamente, podem (re)identificar o indivíduo.
Num outro exemplo, suponhamos que a prefeitura de uma cidade com 100mil habitantes esteja realizando um estudo sobre a doença de Crohn, um tipo raro de doença9, e levanta os dados da população por meio do banco de dados das farmácias.
Os dados que as farmácias locais possuem são os dados de compra de seus clientes e, portanto, dados pessoais. Para promover o sigilo dos clientes, as farmácias utilizam a técnica de pseudonimização para substituir os nomes, CPFs e endereços desses clientes por identificadores numéricos aleatórios e sem significado algum, armazenando essas informações que ligam esses dados diretos aos dados fabricados.
Os outros dados desses clientes, e ainda dados pessoais, como os medicamentos comprados, a data de compra, a profissão do indivíduo e sua idade e gênero são permanecidos em sua forma original e repassados à prefeitura para o estudo.
Ao divulgar o estudo, o jornal da cidade faz uma reportagem dizendo que a doença rara atingiu 1 morador daquela cidade: uma mulher de 57 anos, funcionária do hospital da cidade, que ficou doente no ano 2017.
Para os moradores daquela cidade, ou pelo menos para a comunidade médica, a (re)identificação da pessoa que foi atingida pela doença rara é facilmente feita. Seus colegas, amigos, familiares e até outros habitantes irão associar que o indivíduo divulgado pelo jornal, resultado do estudo, é a pessoa que eles conhecem.
No exemplo citado, vemos que a (re)identificação de um indivíduo, tomado o contexto, pode facilmente ocorrer com poucos dados. No exemplo, citamos apenas cinco. Mas, trazendo para uma realidade em que esses dados estão cada vez em formato digital, a quantidade de dados disponíveis é, em muito, superior.
Essa multidimensionalidade de dados nem sempre é "visível". No exemplo acima, os clientes de farmácias e supermercados possuem um maior controle e ciência dos dados fornecidos, pois fizeram um cadastro, compartilharam dados voluntariamente e são recorrentemente lembrados que estão compartilhando esses dados quando informam seu número de CPF, por exemplo, no momento em que procedem com o pagamento das mercadorias.
Porém, há tantos outros dados que indivíduos fornecem sem uma clareza de que suas informações pessoais estão sendo coletadas. São os casos das câmeras de segurança espalhadas por lojas, shoppings e ruas; o uso de aplicativos e sites de navegação na web e postagem de fotos em redes sociais, para mencionar alguns. A coleta desses dados é realizada com uma constância elevada e nem sempre seus titulares possuem uma visão de que tipo de informação está sendo fornecida.
Dizer que os dados pseudonimizados devem ser considerados dados pessoais e, portanto, devem ter o respaldo da LGPD é defender a proteção dos dados pessoais dentro do próprio texto da lei.
A LGPD, no artigo 5º, inciso I, diz, expressamente, que dado pessoal é informação relacionada a pessoa natural identificada ou identificável. Dessa forma, se dados que, por vezes, não são diretamente associados a um indivíduo, mas, analisados em conjunto com outros dados disponíveis, possuem altas chances de (re)identificação de um indivíduo, esse indivíduo é identificável e, portanto, esses dados devem ser considerados como dados pessoais.
 *Isadora Maria Roseiro Ruiz é pesquisadora e integrante dos Grupos de Pesquisa "Direito, Ética e Inteligência Artificial", "Tutela Jurídica dos Dados Pessoais dos Usuários da Internet" e "Observatório do Marco Civil da Internet", USP – CNPq. Graduada pela Faculdade de Direito de Franca – FDF. Advogada. Associada fundadora do Instituto Avançado de Proteção de Dados – IAPD.
*Isadora Maria Roseiro Ruiz é pesquisadora e integrante dos Grupos de Pesquisa "Direito, Ética e Inteligência Artificial", "Tutela Jurídica dos Dados Pessoais dos Usuários da Internet" e "Observatório do Marco Civil da Internet", USP – CNPq. Graduada pela Faculdade de Direito de Franca – FDF. Advogada. Associada fundadora do Instituto Avançado de Proteção de Dados – IAPD.
__________
1 RUIZ, E. E. S. Anonimização, Pseudonimização e Desanonimização de Dados Pessoais. In: LIMA, Cíntia Rosa Pereira de. (coord.) Comentários à lei geral de proteção de dados: Lei n. 13.709/2018, com alteração da lei n. 13.853/2019. São Paulo: Almedina, 2020. pp. 101-122.
2 Artigo 12, da lei n. 13.709, de 14 de agosto de 2018, diz: "Os dados anonimizados não serão considerados dados pessoais para os fins desta Lei, salvo quando o processo de anonimização ao qual foram submetidos for revertido, utilizando exclusivamente meios próprios, ou quando, com esforços razoáveis, puder ser revertido".
3 OHM, Paul. Broken promises of privacy: responding to the surprising failure of anonymization. In: UCLA Law Review, v.57, pp.1701-1777, 2010.
4 ICO. What is personal data? In: Information Comissioner’s Office, Wilmslow, 2020. Disponível em: . Acesso em 18 ago. 2020.
5 POSSI, Ana Carolina Benincasa. O que é anonimização e pseudoanonimização de dados? Disponível aqui, acessado em 20 de agosto de 2020.
6 ICO. What is personal data? In Information Comissioner’s Office, Wilmslow, 2020. Disponível em: . Acesso em 18 ago. 2020.
7 Thomson Reuters. GDPR: Recitals. In Thomson Reuters Practical Law, Londres, 2020. Disponível aqui. Acesso em 18 ago. 2020.
8 Ruiz, E. E S. e Lima, C.R.P. "Perspectivas Regulatórias de Anonimização no Brasil a partir da Lei Geral de Proteção de Dados Pessoais" (comunicação pessoal de 10 de agosto de 2020).
9 VICTORIA, Carlos Roberto; SASSAK, Ligia Yukie; NUNES, Hélio Rubens de Carvalho. Incidence and prevalence rates of inflammatory bowel diseases, in midwestern of São Paulo State, Brazil. Arq. Gastroenterol., São Paulo , v. 46, n. 1, p. 20-25, Mar. 2009. Disponível em: . Acesso em 18 ago. 2020.